
Obciążenia związane ze sztuczną inteligencją przekraczają możliwości chłodzenia powietrzem. Redundancja N+1 może przyczynić się do zmniejszenia ryzyka przerw w działaniu systemu.
W dzisiejszych środowiskach o dużej gęstości nawet krótka przerwa w chłodzeniu może spowodować gwałtowny wzrost temperatury. Ponieważ szafy serwerowe zużywają 100 kilowatów (kW) lub więcej, jest mniej miejsca na błędy i mniej czasu na reakcję.
Chłodzenie stało się kwestią o kluczowym znaczeniu dla niezawodności. Według badania Uptime Institute „2025 Global Data Center Survey” 14% poważnych awarii jest obecnie związanych z usterkami systemów chłodzenia. Kwestie związane z zasilaniem nadal zajmują pierwsze miejsce, ale tuż za nimi plasuje się chłodzenie (patrz rysunek 1).
Wraz z wdrażaniem infrastruktury zoptymalizowanej pod kątem sztucznej inteligencji obiekty osiągają nowy poziom wydajności i gęstości mocy. Na przykład pojedyncza szafa z systemami NVIDIA GB300 NVL72 może pobierać ponad 120 kW, znacznie przekraczając ograniczenia konwencjonalnych rozwiązań chłodniczych. Daje to okazję do ponownego przemyślenia sposobu projektowania systemów chłodzenia.
W tym miejscu pojawia się redundancja N+1.
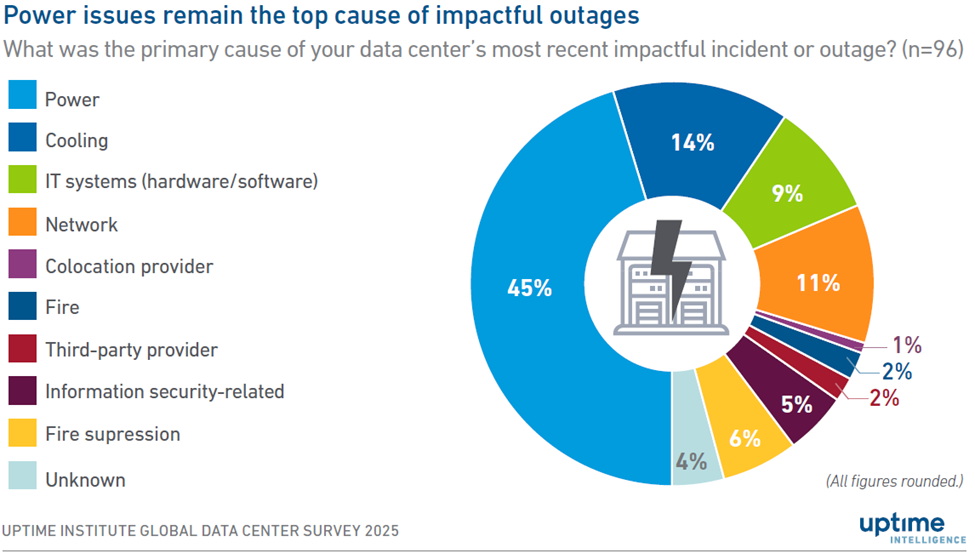
Rysunek 1. Według badania przeprowadzonego przez Uptime Institute w 2025 r. awarie dystrybucji energii powodują 45% poważnych przerw w dostawach energii, natomiast systemy chłodzenia odpowiadają za 14% przypadków, co stanowi stałe ryzyko występujące w jednym na siedem przypadków. Wraz ze wzrostem gęstości szaf, wskaźnik awarii chłodzenia może wzrosnąć bez odpowiednich środków zaradczych. Rozwiązaniem są proaktywne środki: redundantne systemy termiczne i architektury chłodzenia wspierane przez zasilacze awaryjne (UPS), zaprojektowane z myślą o przyszłych progach mocy. Źródło: Instytut Uptime
Co oznacza N+1 w systemach chłodzenia
Redundancja N+1 dodaje jedną dodatkową jednostkę chłodzącą ponad to, co jest wymagane do pokrycia pełnego obciążenia termicznego. Jeśli system wymaga czterech agregatów chłodniczych lub jednostek dystrybucji chłodziw (CDU), aby utrzymać wydajność, N+1 oznacza zainstalowanie pięciu. Jeśli jedna jednostka ulegnie awarii, pozostałe mogą nadal obsługiwać obciążenie bez zakłóceń.
Takie podejście ma zastosowanie w całym łańcuchu termicznym, w tym w systemach obsługi powietrza, pętlach chłodzenia cieczą, agregatach chłodniczych, pompach i elementach sterujących. Jednakże redundancja musi być zaprojektowana w systemie.
Zapasowa jednostka CDU nie ma większego znaczenia, jeśli cała pętla jest zasilana przez jeden panel sterowania.
N+1 nie eliminuje awarii. Może pomóc w zarządzaniu przerwami w działaniu systemu.
Co oznacza N w redundancji?
W przypadku redundancji centrum danych, N odnosi się do liczby komponentów lub jednostek potrzebnych do obsługi pełnej wydajności operacyjnej systemu. Jest to podstawowa wielkość wymagana do normalnego działania bez żadnych kopii zapasowych.
Strategie redundancji dla obliczeń o wysokiej wydajności
Wielu operatorów łączy poziomy nadmiarowości. Obiekt może być zasilany napięciem 2N z chłodzeniem N+1. Ta równowaga zależy od obciążenia pracą i tolerancji na ryzyko. Jednak wraz ze wzrostem częstotliwości awarii układów chłodzenia, redundancja N+1 stała się minimalnym standardem branżowym w projektowaniu systemów chłodzenia w nowoczesnych centrach danych.
|
Poziom redundancji |
Konfiguracja |
Ochrona przed awarią |
Dostosowanie strategii chłodzenia |
Typowe przypadki użycia |
|
N |
Brak nadmiarowości; wszystkie systemy działają z pełną wydajnością |
Brak ochrony; każda awaria powoduje przestoje |
Niezalecane w przypadku HPC ze względu na ryzyko wystąpienia odchyleń termicznych |
Laboratoria rozwojowe, niekrytyczne środowiska testowe |
|
N+1 |
Jedna jednostka rezerwowa o większej pojemności niż wymagana |
Ochrona przed pojedynczymi awariami |
Nadaje się do redundancji CRAC/CDU/pompy na poziomie szafy lub pętli |
Podstawowe wdrożenia HPC na małą skalę |
|
N+2 |
Dwa komponenty zapasowe przekraczające wymaganą pojemność |
Ochrona przed dwoma równoczesnymi awariami |
Stosowane w przypadku wysokich wymagań dotyczących czasu pracy, ale przy zachowaniu wrażliwości na koszty. |
|
|
2N |
Pełna duplikacja całego układu chłodzenia |
Cały system może ulec awarii bez powodowania zakłóceń |
|
Laboratoria krajowe, komercyjne prace modelarskie |
|
2N+1 |
Pełne powielanie plus dodatkowy komponent zapasowy |
Wytrzymuje wiele awarii w różnych systemach |
Wysokiej klasy chłodzenie cieczą z izolowanymi ścieżkami, nadmiarowymi elementami sterującymi i oprzyrządowaniem |
Klastry AI w skali chmury, witryny HPC klasy IV |
|
Rozproszone N+1 |
Nadmiarowość wbudowana w podsystemy modułowe |
Lokalne przełączanie awaryjne w ramach każdego modułu |
Idealne rozwiązanie dla kontenerowej lub prefabrykowanej infrastruktury HPC |
Modułowa technologia HPC, węzły brzegowe AI z wbudowanym chłodzeniem |
Korzyści operacyjne wynikające z redundancji N+1
Redundancja N+1 w systemach chłodzenia umożliwia zakładom utrzymanie wydajności w przypadku problemów ze sprzętem, planowanej konserwacji lub przenoszenia obciążeń.
Chroni sprawność chłodzenia podczas awarii sprzętu
W przypadku awarii agregatu chłodniczego lub CDU jednostka rezerwowa może przejąć kontrolę przy minimalnym wpływie na wydajność. Zapobiega to znacznym wahaniom temperatury, które w przeciwnym razie mogłyby spowodować dławienie lub wyłączenie urządzenia.
Umożliwia konserwację bez zakłóceń
Zespoły mogą serwisować lub wymieniać komponenty bez przechodzenia chłodzenia w tryb offline. W środowiskach AI z ciągłymi wysokimi obciążeniami elastyczność jest niezbędna.
Zmniejsza obciążenie dzięki podziałowi obciążeń
W wielu systemach wszystkie agregaty chłodnicze pracują razem przy częściowym obciążeniu, nawet te redundantne. Zmniejsza to obciążenie komponentów i sprawia, że przejścia między awariami przebiegają płynniej.
Poprawia izolację awarii
Jednostki nadmiarowe są często zasilane i sterowane oddzielnie. Pomaga to ograniczyć lokalne usterki, takie jak błędy wyłączników lub sterowników PLC (programowalnych sterowników logicznych), zanim się rozprzestrzenią.
Obsługa walidacji na żywo
Dzięki N+1 można symulować awarie w rzeczywistych warunkach obciążenia. Pozwala to na testowanie czasu reakcji, logiki failover i zachowania termicznego przy mniejszym ryzyku.
Usuwanie luk, zanim spowodują awarię
Redundancja N+1 nie rozwiązuje każdego problemu, ale daje czas, kiedy ma to największe znaczenie: podczas awarii lub okna serwisowego. Jest to obecnie podstawa chłodzenia obciążeń o dużej gęstości, pomagając obiektom wyprzedzać zapotrzebowanie, utrzymywać ciągłość działania i skalować z pewnością.
Co robić dalej:
Przejrzyj swoją architekturę termiczną. Dowiedz się, ile jednostek potrzebujesz, aby pozostać online i czy masz niezbędny bufor. Ten bufor jest twoim +1.
Ocena wymagań dotyczących redundancji podczas wstępnego planowania może pomóc w zapewnieniu wydajności operacyjnej.
Chcesz zoptymalizować chłodzenie pod kątem obciążeń o dużej gęstości? Skontaktuj się z Vertiv i poznaj strategie chłodzenia cieczą dostosowane do potrzeb Twojego centrum danych.

Powiązane artykuły


