
AI workloads are exceeding the limits of air cooling. N+1 redundancy can contribute to reduced risk of system interruptions.
In today’s high-density environments, even a short cooling disruption can trigger a rapid temperature spike. As racks push 100 kilowatts (kW) or more, there’s less room for error, and less time to react.
Cooling has become a frontline reliability issue. According to Uptime Institute’s 2025 Global Data Center Survey, 14% of serious outages are now linked to cooling failures. Power issues still lead, but cooling is a close second (see Figure 1).
As facilities deploy AI-optimized infrastructure, they’re reaching new levels of performance and power density. For example, a single rack of NVIDIA GB300 NVL72 systems can draw more than 120 kW, pushing well beyond the limits of conventional cooling designs. This creates an opportunity to rethink how cooling is designed.
That’s where N+1 redundancy comes in.
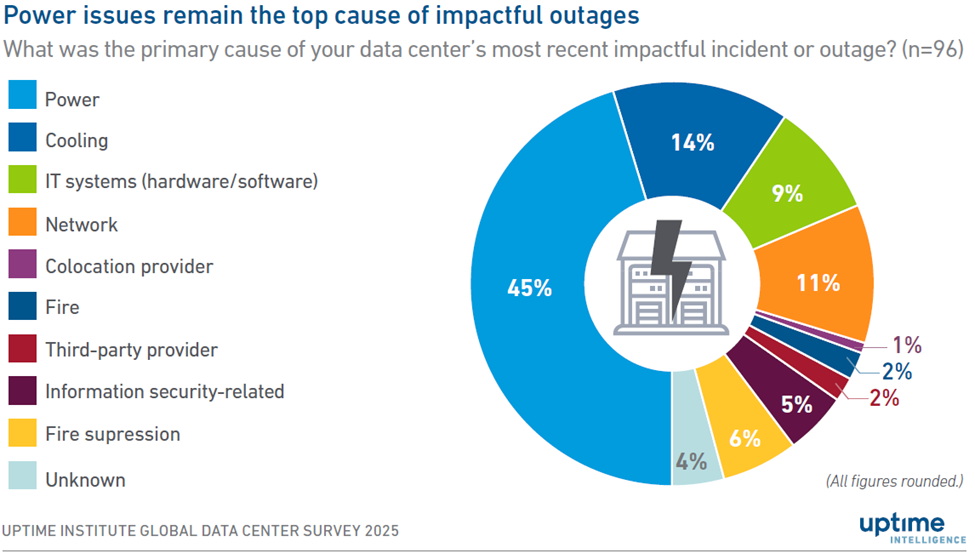
Figure 1. According to Uptime Institute's 2025 survey, power distribution failures cause 45% of serious outages, while cooling systems account for 14%—a persistent one-in-seven risk. As rack densities climb, the cooling failure rate may rise without adequate mitigation measures. The solution lies in proactive measures: redundant thermal systems and uninterruptible power supply (UPS)-backed cooling architectures designed for tomorrow’s power thresholds. Source: Uptime Institute
What N+1 means in cooling systems
N+1 redundancy adds one extra cooling unit beyond what is required to meet the full thermal load. If your system needs four chillers or coolant distribution units (CDUs) to maintain performance, N+1 means installing five. If one unit fails, the others can still handle the load without interruption.
This approach applies across the thermal chain, including air handlers, liquid cooling loops, chillers, pumps, and controls. But redundancy has to be designed into the system.
A spare CDU means little if a single control panel powers the whole loop.
N+1 doesn’t eliminate failure. It can help manage system interruptions.
What does N mean in redundancy?
In data center redundancy, N refers to the number of components or units needed to support the system’s full operational capacity. It’s the baseline amount required for normal operation without any backups.
Redundancy strategies for high-performance computing
Many operators mix redundancy levels. A facility might run 2N power with N+1 cooling. That balance depends on the workload and risk tolerance. But as cooling becomes a more common failure point, N+1 redundancy has become the industry-standard minimum for cooling system design in modern data centers.
|
Redundancy level |
Configuration |
Failure protection |
Cooling strategy alignment |
Typical use cases |
|
N |
No redundancy; all systems run at full capacity |
No protection; any failure causes downtime |
Not recommended for HPC due to risk of thermal excursions |
Development labs, non-critical test environments |
|
N+1 |
One backup unit beyond required capacity |
Single failure protection |
Suitable for CRAC/CDU/pump redundancy at rack or loop level |
Entry-level HPC, small-scale AI deployments |
|
N+2 |
Two backup components beyond required capacity |
Protection from two concurrent failures |
Used when uptime requirements are high, but cost sensitivity remains |
|
|
2N |
Full duplication of entire cooling system |
One entire system can fail without disruption |
|
National labs, commercial modeling workloads |
|
2N+1 |
Full duplication plus additional spare component |
Tolerates multiple failures across systems |
High-end liquid cooling with isolated paths, redundant controls, and instrumentation |
Cloud-scale AI clusters, Tier IV-grade HPC sites |
|
Distributed N+1 |
Redundancy embedded across modular subsystems |
Localized failover within each module |
Ideal for containerized or prefabricated HPC infrastructure |
Modular HPC, edge AI nodes with on-board cooling |
Operational benefits of N+1 redundancy
N+1 redundancy in cooling systems enables facilities to maintain performance in case of equipment issues, planned maintenance, or shifting loads.
Protects cooling uptime during equipment faults
If a chiller or CDU fails, the backup unit can take over with minimal performance impact. This prevents significant thermal swings that might otherwise force throttling or trigger shutdowns.
Enables maintenance without disruption
Teams can service or replace components without taking cooling offline. For AI environments with continuous high loads, flexibility is essential.
Reduces stress through load sharing
In many systems, all cooling units run together at partial load—even the redundant one. That lowers stress on components and makes failure transitions smoother.
Improves fault isolation
Redundant units are often powered and controlled separately. That helps contain local faults like breaker trips or programmable logic controller (PLC) errors before they spread.
Supports live validation
With N+1 in place, you can simulate failures under real load conditions. That allows you to test response times, failover logic, and thermal behavior with less risk.
Closing the gaps before they break
N+1 redundancy doesn’t solve every problem, but it gives you time when it matters most: during a failure or a service window. It’s now the baseline for cooling high-density workloads, helping facilities stay ahead of demand, maintain uptime, and scale with confidence.
What to do next:
Review your thermal architecture. Know how many units you need to stay online, and whether you have a buffer. That buffer is your +1.
Evaluating redundancy requirements during initial planning can help support operational efficiency.
Looking to optimize cooling for high-density workloads? Talk to Vertiv and explore liquid cooling strategies tailored to your data center.




