
AIワークロードは空冷の限界を超えています。N+1冗長性は、システムの中断リスクの低減に寄与する可能性がある。
今日の高密度環境では、短時間の冷却中断でも急激な温度上昇を引き起こす可能性があります。ラックが100キロワット(kW)以上を押すと、エラーの余地が減り、反応する時間が短縮されます。
冷却は最前線の信頼性の問題となっています。Uptime Instituteの2025年グローバルデータセンター調査によると、深刻な停電の14%が冷却障害と関連しています。電源の問題は依然として発生しますが、冷却は1秒近くです(図1を参照)。
施設が AI 最適化インフラストラクチャを導入するにつれ、パフォーマンスと電力密度が新たなレベルに達しています。たとえば、NVIDIA GB300 NVL72 システムの 1 ラックで 120 kW 以上の電力を消費でき、従来の冷却設計の限界をはるかに超えています。これにより、冷却がどのように設計されているかを再考する機会が生まれます。
そこでN+1冗長化が登場します。
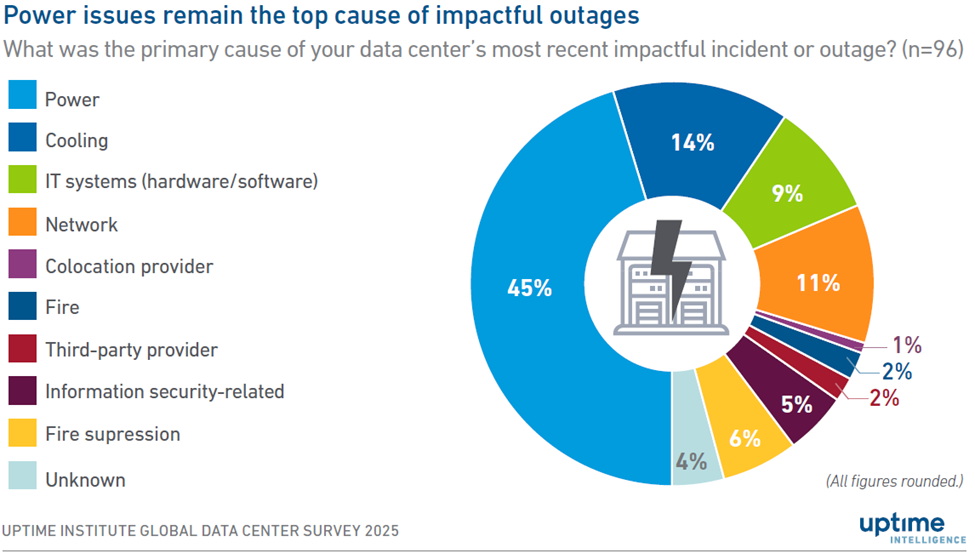
図1. Uptime Instituteの2025年の調査によると、配電障害は深刻な停電の45%を引き起こし、冷却システムは14%を占め、7分の1のリスクが持続しています。ラック密度が上昇するにつれて、適切な緩和策なしで冷却故障率が上昇する可能性があります。このソリューションは、将来の電力閾値のために設計された冗長な熱システムや無停電電源装置(UPS)がバックアップする冷却アーキテクチャなどの事前対策にかかっています。出典:アップタイム・インスティテュート
冷却システムにおけるN+1の意味
N+1冗長化は、熱負荷を完全に満たすために必要な範囲を超えて1台の冷却ユニットを追加します。システムの性能を維持するために4台のチラーまたはクーラント分配ユニット(CDU)が必要な場合、N+1は5台を設置することを意味します。1つのユニットが故障しても、他のユニットは中断することなく負荷を処理できます。
このアプローチは、エアハンドラー、液体冷却ループ、チラー、ポンプ、制御装置など、サーマルチェーン全体に適用されます。ただし、冗長性はシステム内に設計する必要があります。
予備のCDUは、1つのコントロールパネルがループ全体に電力を供給するとほとんど意味しません。
N+1は失敗をなくさない。システムの中断を管理するのに役立ちます。
冗長性におけるNの意味とは?
データセンターの冗長性では、Nはシステムのフル稼働容量をサポートするのに必要なコンポーネントまたはユニットの数を指します。これは、バックアップなしでの通常の操作に必要なベースライン量です。
高性能コンピューティングの冗長化戦略
多くのオペレータは冗長レベルを混合します。施設は、N+1冷却で2N電源を稼働させる場合があります。このバランスは、ワークロードとリスク許容度によって異なります。しかし、冷却が一般的な障害ポイントになるにつれて、N+1冗長性は、現代のデータセンターにおける冷却システム設計の業界標準の最小値となっています。
|
冗長レベル |
構成 |
故障保護 |
冷却戦略の調整 |
一般的な使用例 |
|
N さん |
冗長性なし。すべてのシステムがフルキャパシティで稼働 |
保護機能なし。故障によりダウンタイムが発生する |
温度逸脱のリスクがあるため、HPCには推奨されない |
開発ラボ、重要でないテスト環境 |
|
N+1 |
必要な容量を超えるバックアップユニット1台 |
単一障害保護 |
ラックまたはループレベルでのCRAC/CDU/ポンプの冗長性に最適 |
エントリーレベルのHPC、小規模AI導入 |
|
N+2 |
必要な容量を超える2つのバックアップコンポーネント |
2つの同時障害からの保護 |
アップタイム要件は高いが、コストの感度が維持される場合に使用 |
|
|
2N |
冷却システム全体の完全な二重化 |
1つのシステム全体が中断なく故障する可能性がある |
|
国立研究所、商業モデリングワークロード |
|
2N+1 |
フル二重化と予備部品の追加 |
システム全体で複数の障害に耐えられる |
絶縁経路、冗長制御、および計装を備えたハイエンドの液冷 |
クラウドスケールのAIクラスター、ティアIVグレードのHPCサイト |
|
分散型N+1 |
モジュール式サブシステムに埋め込まれた冗長性 |
各モジュール内のローカライズされたフェイルオーバー |
コンテナ化またはプレハブHPCインフラストラクチャに最適 |
オンボード冷却機能付きモジュラー HPC、エッジ AI ノード |
N+1冗長化による運用上のメリット
冷却システムのN+1冗長性により、設備の問題、計画的なメンテナンス、または負荷のシフトが発生した場合に、施設はパフォーマンスを維持できます。
機器の故障時の冷却アップタイムを保護
チラーまたはCDUが故障した場合、バックアップユニットは性能への影響を最小限に抑えながら引き継ぐことができます。これにより、スロットルを強制したりシャットダウンをトリガーする可能性のある重大な熱スイングを防止します。
中断なくメンテナンスが可能
チームは、冷却をオフラインにすることなく、コンポーネントを修理または交換できます。継続的な高負荷のAI環境では、柔軟性が不可欠です。
負荷分散によるストレス軽減
多くのシステムでは、すべての冷却ユニットが部分負荷で一緒に動作します。冗長ユニットも同じです。これにより、コンポーネントへのストレスが軽減され、障害の移行がスムーズになります。
障害分離を改善
冗長ユニットは多くの場合、個別に電源供給および制御されます。これにより、ブレーカートリップやプログラマブル・ロジック・コントローラ(PLC)エラーなどのローカルフォルトが拡散する前に封じ込めることができます。
ライブ検証をサポート
N+1を導入すると、実際の負荷条件下での故障をシミュレーションできます。これにより、より少ないリスクで応答時間、フェイルオーバーロジック、熱動作をテストできます。
ギャップが解消される前にギャップを埋める
N+1冗長化はすべての問題を解決するわけではありませんが、障害発生時やサービスウィンドウなど、最も重要なときに時間を提供します。今では、高密度ワークロードの冷却のベースラインとなり、施設が需要の先を行き、稼働時間を維持し、自信を持って拡張するのに役立ちます。
次にすべきこと:
サーマルアーキテクチャを確認します。オンライン状態を維持するのに必要なユニット数と、バッファがあるかどうかを把握します。そのバッファは+1です。
初期計画時の冗長性要件の評価は、運用効率の向上に役立ちます。
高密度ワークロードの冷却を最適化したいですか? Vertivにご相談の上、データセンターに合わせた液冷戦略をご覧ください。



